Get Started with Dgraph - Basic Types and Operations
Welcome to the third tutorial of getting started with Dgraph.
In the previous tutorial, we learned about CRUD operations using UIDs. We also learned about traversals and recursive traversals.
In this tutorial, we’ll learn about Dgraph’s basic types and how to query for them. Specifically, we’ll learn about:
- Basic data types in Dgraph.
- Querying for predicate values.
- Indexing.
- Filtering nodes.
- Reverse traversing.
Check out the accompanying video:
Let’s start by building the graph of a simple blog application. Here’s the Graph model of our application:
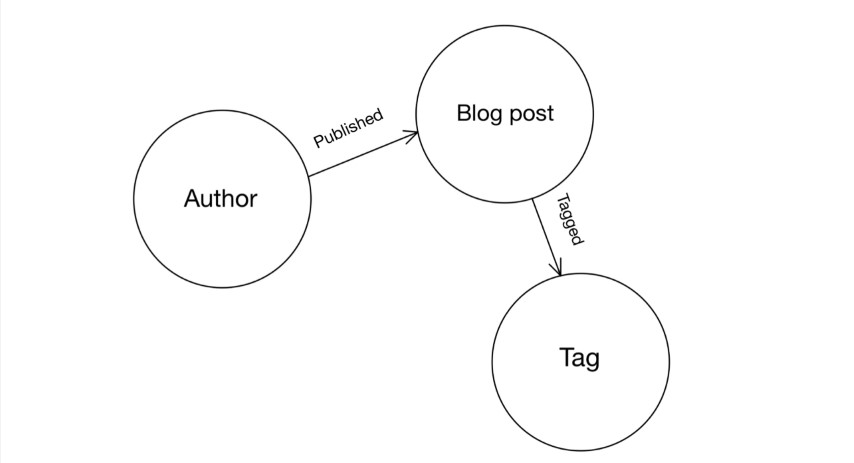
The above graph has three entities: Author, Blog posts, and Tags. The nodes in the graph represent these entities. For the rest of the tutorial, we’ll call the nodes representing a blog as a blog post node and the node presenting a tag as a tag node, and so on.
You can see from the graph model that these entities are related:
- Every Author has one or more blog posts.
The published edge relates the blogs to their authors. These edges start from an author node and point to a blog post node.
- Every Blog post has one or more tags.
The tagged edge relates the blog posts to their tags. These edges emerge from a blog post node and point to a tag node.
Let’s build our graph.
Go to Ratel, click on the mutate tab, paste the following mutation, and click Run.
{
"set": [
{
"author_name": "John Campbell",
"rating": 4.1,
"published": [
{
"title": "Dgraph's recap of GraphQL Conf - Berlin 2019",
"url": "https://blog.dgraph.io/post/graphql-conf-19/",
"content": "We took part in the recently held GraphQL conference in Berlin. The experience was fascinating, and we were amazed by the high voltage enthusiasm in the GraphQL community. Now, we couldn’t help ourselves from sharing this with Dgraph’s community! This is the story of the GraphQL conference in Berlin.",
"likes": 100,
"dislikes": 4,
"publish_time": "2018-06-25T02:30:00",
"tagged": [
{
"uid": "_:graphql",
"tag_name": "graphql"
},
{
"uid": "_:devrel",
"tag_name": "devrel"
}
]
},
{
"title": "Dgraph Labs wants you!",
"url": "https://blog.dgraph.io/post/hiring-19/",
"content": "We recently announced our successful Series A fundraise and, since then, many people have shown interest to join our team. We are very grateful to have so many people interested in joining our team! We also realized that the job openings were neither really up to date nor covered all of the roles that we are looking for. This is why we decided to spend some time rewriting them and the result is these six new job openings!.",
"likes": 60,
"dislikes": 2,
"publish_time": "2018-08-25T03:45:00",
"tagged": [
{
"uid": "_:hiring",
"tag_name": "hiring"
},
{
"uid": "_:careers",
"tag_name": "careers"
}
]
}
]
},
{
"author_name": "John Travis",
"rating": 4.5,
"published": [
{
"title": "How Dgraph Labs Raised Series A",
"url": "https://blog.dgraph.io/post/how-dgraph-labs-raised-series-a/",
"content": "I’m really excited to announce that Dgraph has raised $11.5M in Series A funding. This round is led by Redpoint Ventures, with investment from our previous lead, Bain Capital Ventures, and participation from all our existing investors – Blackbird, Grok and AirTree. With this round, Satish Dharmaraj joins Dgraph’s board of directors, which includes Salil Deshpande from Bain and myself. Their guidance is exactly what we need as we transition from building a product to bringing it to market. So, thanks to all our investors!.",
"likes": 139,
"dislikes": 6,
"publish_time": "2019-07-11T01:45:00",
"tagged": [
{
"uid": "_:annoucement",
"tag_name": "annoucement"
},
{
"uid": "_:funding",
"tag_name": "funding"
}
]
},
{
"title": "Celebrating 10,000 GitHub Stars",
"url": "https://blog.dgraph.io/post/10k-github-stars/",
"content": "Dgraph is celebrating the milestone of reaching 10,000 GitHub stars 🎉. This wouldn’t have happened without all of you, so we want to thank the awesome community for being with us all the way along. This milestone comes at an exciting time for Dgraph.",
"likes": 33,
"dislikes": 12,
"publish_time": "2017-03-11T01:45:00",
"tagged": [
{
"uid": "_:devrel"
},
{
"uid": "_:annoucement"
}
]
}
]
},
{
"author_name": "Katie Perry",
"rating": 3.9,
"published": [
{
"title": "Migrating data from SQL to Dgraph!",
"url": "https://blog.dgraph.io/post/migrating-from-sql-to-dgraph/",
"content": "Dgraph is rapidly gaining reputation as an easy to use database to build apps upon. Many new users of Dgraph have existing relational databases that they want to migrate from. In particular, we get asked a lot about how to migrate data from MySQL to Dgraph. In this article, we present a tool that makes this migration really easy: all a user needs to do is write a small 3 lines configuration file and type in 2 commands. In essence, this tool bridges one of the best technologies of the 20th century with one of the best ones of the 21st (if you ask us).",
"likes": 20,
"dislikes": 1,
"publish_time": "2018-08-25T01:44:00",
"tagged": [
{
"uid": "_:tutorial",
"tag_name": "tutorial"
}
]
},
{
"title": "Building a To-Do List React App with Dgraph",
"url": "https://blog.dgraph.io/post/building-todo-list-react-dgraph/",
"content": "In this tutorial we will build a To-Do List application using React JavaScript library and Dgraph as a backend database. We will use dgraph-js-http — a library designed to greatly simplify the life of JavaScript developers when accessing Dgraph databases.",
"likes": 97,
"dislikes": 5,
"publish_time": "2019-02-11T03:33:00",
"tagged": [
{
"uid": "_:tutorial"
},
{
"uid": "_:devrel"
},
{
"uid": "_:javascript",
"tag_name": "javascript"
}
]
}
]
}
]
}
Our Graph is ready!
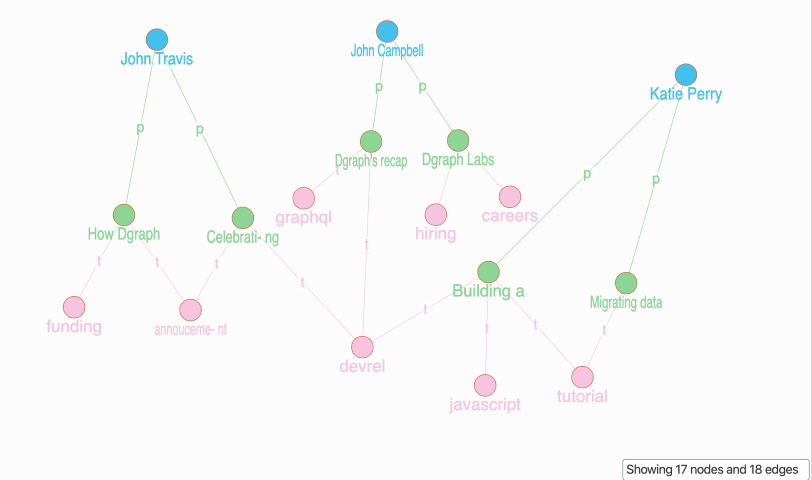
Our Graph has:
- Three blue author nodes.
- Each author has two blog posts each - six in total - which are represented by the green nodes.
- The tags of the blog posts are in pink. You can see that there are 8 unique tags, and some of the blogs share a common tag.
Data types for predicates
Dgraph automatically detects the data type of its predicates. You can see the auto-detected data types using the Ratel UI.
Click on the schema tab on the left and then check the Type column. You’ll see the predicate names and their corresponding data types.
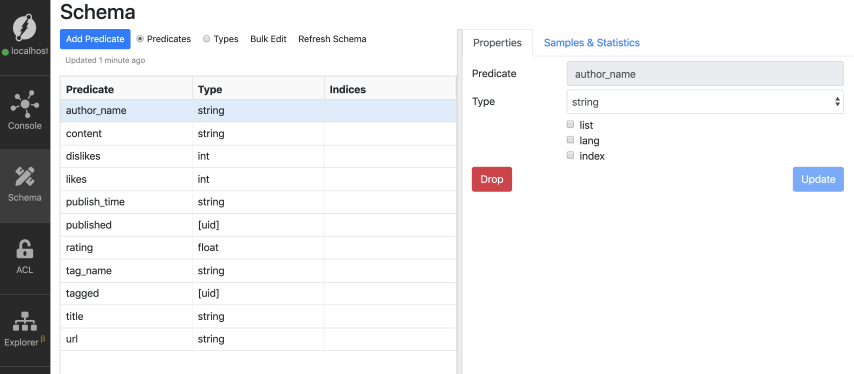
These data types include string, float, and int, and uid. Besides them, Dgraph also offers three more basic data types: geo, dateTime, and bool.
The uid types represent predicates between two nodes. In other words, they represent edges connecting two nodes.
You might have noticed that the published and tagged predicates are of type uid array ([uid]). UID arrays represent a collection of UIDs. This is used to represent one to many relationships.
For instance, we know that an author can publish more than one blog. Hence, there could be more than one published edge emerging from a given author node, each pointing to a different blog post of the author.
Dgraph’s v1.1 release introduced the type system feature. This feature made it possible to create custom data types by grouping one or more predicates. But in this tutorial, we’ll only focus on the basic data types.
Also, notice that there are no entries in the indexes column. We’ll talk about indexes in detail shortly.
Querying for predicate values
First, let’s query for all the Authors and their ratings:
{
authors_and_ratings(func: has(author_name)) {
uid
author_name
rating
}
}
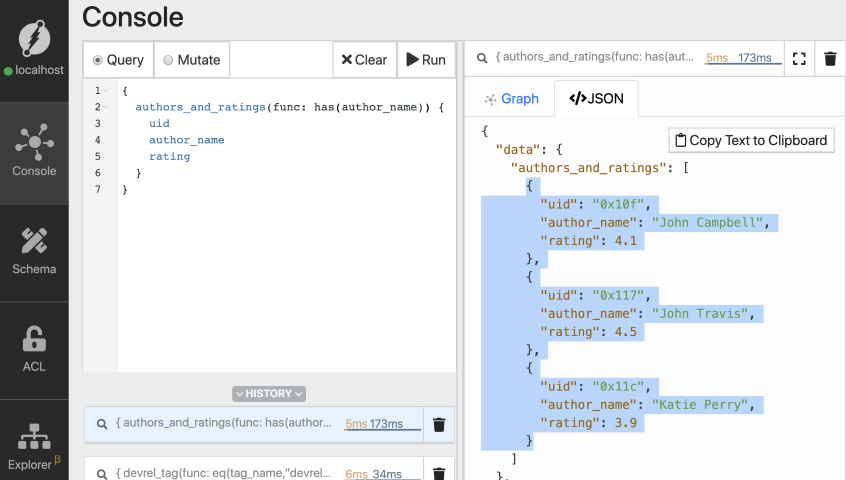
Refer to the first episode if you have any questions related to the structure of the query in general.
We have 3 authors in total in our dataset. Now, let’s find the best authors. Let’s query for authors whose rating is 4.0 or more.
In order to achieve our goal, we need a way to select nodes that meets certain criteria (e.g., rating > 4.0). You can do this by using Dgraph’s built-in comparator functions. Here’s the list of comparator functions available in Dgraph:
| comparator function name | Full form |
|---|---|
| eq | equals to |
| lt | less than |
| le | less than or equal to |
| gt | greater than |
| ge | greater than or equal to |
There are a total of five comparator functions in Dgraph. You can use any of them alongside the func keyword in your queries.
The comparator function takes two arguments. One is the predicate name and the other is its comparable value. Here are a few examples.
| Example usage | Description |
|---|---|
| func: eq(age, 60) | Return nodes with age predicate equal to 60. |
| func: gt(likes, 100) | Return nodes with a value of likes predicate greater than 100. |
| func: le(dislikes, 10) | Return nodes with a value of dislikes predicates less than or equal to 10. |
Now, guess the comparator function we should use to select author nodes with a rating of 4.0 or more.
If you think it should be the greater than or equal to(ge) function, then you’re right!
Let’s try it out.
{
best_authors(func: ge(rating, 4.0)) {
uid
author_name
rating
}
}
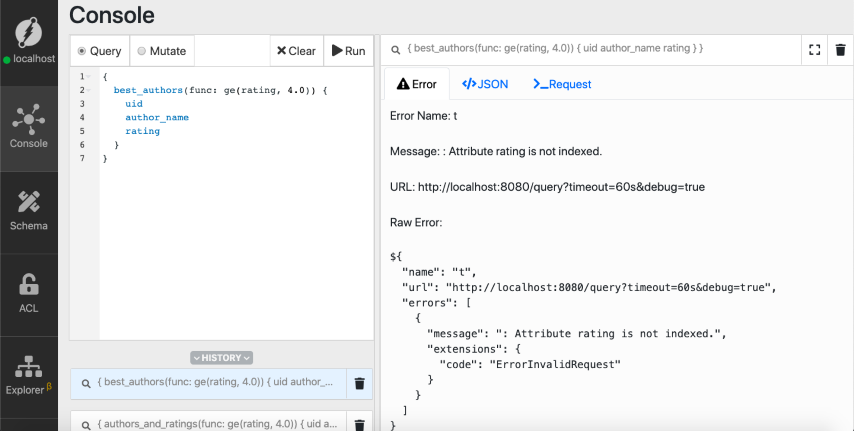
We got an error! The index for the rating predicate is missing. You cannot query for the value of a predicate unless you’ve added an index for it.
Let’s learn more about indexes in Dgraph and also how to add them.
Indexing in Dgraph
Indexes are used to speed up your queries on predicates. They have to be explicitly added to a predicate when they are required. That is, only when you need to query for the value of a predicate.
Also, there’s no need to anticipate the indexes to be added right at the beginning. You can add them as you go along.
Dgraph offers different types of indexes. The choice of index depends on the data type of the predicate.
Here is the table containing data types and the set of indexes that can be applied to them.
| Data type | Available index types |
|---|---|
| int | int |
| float | float |
| string | hash, exact, term, fulltext, trigram |
| bool | bool |
| geo | geo |
| dateTime | year, month, day, hour |
Only string and dateTime data types have an option for more than one index type.
Let’s create an index on the rating predicate. Ratel UI makes it super simple to add an index.
Here’s the sequence of steps:
- Go to the schema tab on the left.
- Click on the
ratingpredicate from the list. - Tick the index option in the Properties UI on the right.
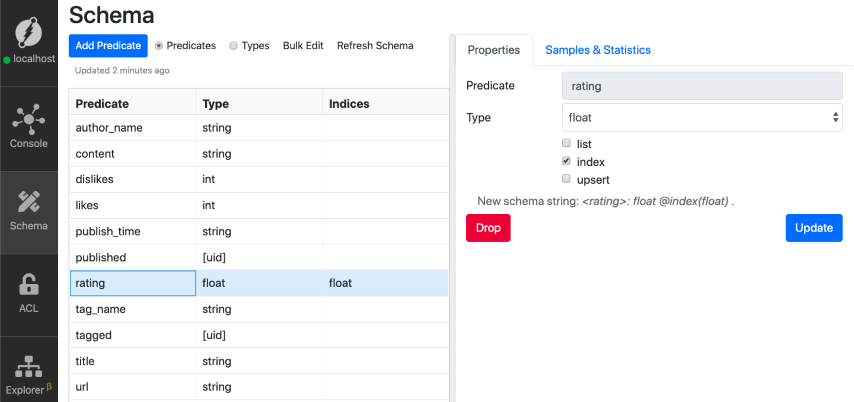
We successfully added the index for rating predicate! Let’s rerun our previous query.
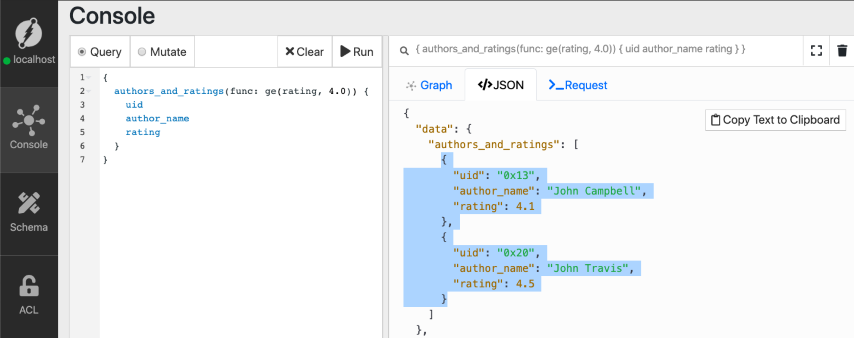
We successfully queried for Author nodes with a rating of 4.0 or more. How about we also fetch the Blog posts of these authors?
We already know that the published edge points from an author node to a blog post node. So fetching the blog posts of the author nodes is simple. We need to traverse the published edge starting from the author nodes.
{
authors_and_ratings(func: ge(rating, 4.0)) {
uid
author_name
rating
published {
title
content
dislikes
}
}
}
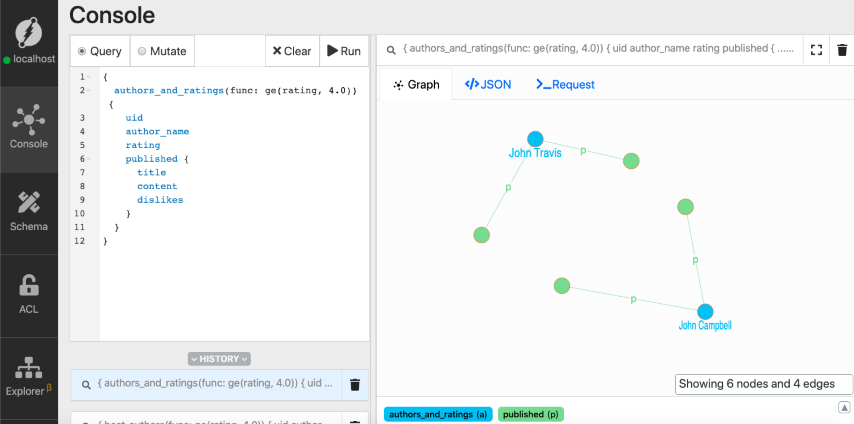
Check out our previous tutorial if you have questions around graph traversal queries.
Similarly, let’s extend our previous query to fetch the tags of these blog posts.
{
authors_and_ratings(func: ge(rating, 4.0)) {
uid
author_name
rating
published {
title
content
dislikes
tagged {
tag_name
}
}
}
}
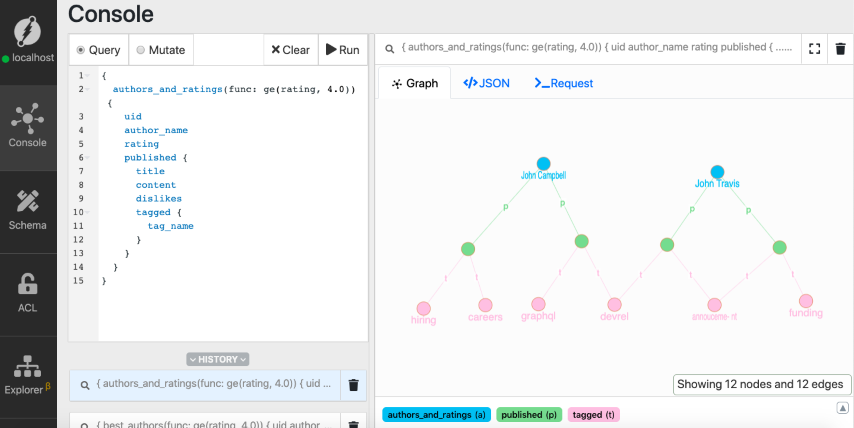
Note: Author nodes are in blue, blogs posts in green, and tags in pink.
We have two authors, four blog posts, and their tags in the result. If you take a closer look at the result, there’s a blog post with 12 dislikes.
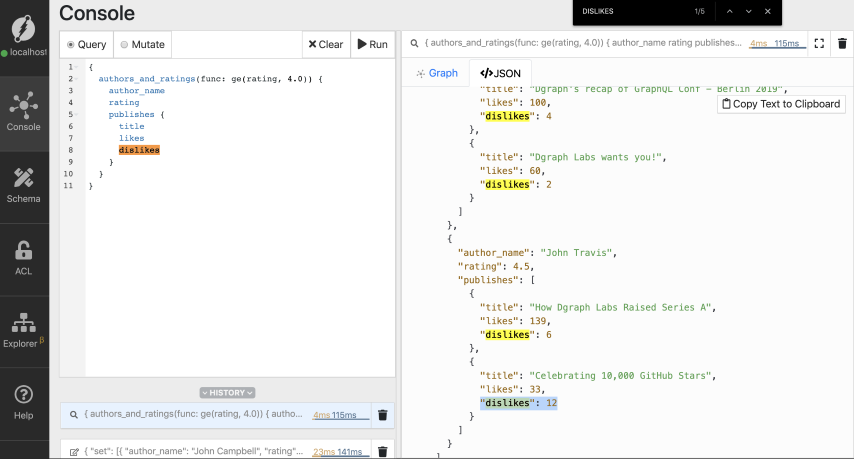
Let’s filter and fetch only the popular blog posts. Let’s query for only those blog posts with fewer than 10 dislikes.
To achieve that, we need to express the following statement as a query to Dgraph:
Hey, traverse the published edge, but only return those blogs with fewer than 10 dislikes
Can we also filter the nodes during traversals? Yes, we can! Let’s learn how to do that in our next section.
Filtering traversals
We can filter the result of traversals by using the @filter directive. You can use any of the Dgraph’s comparator functions with the @filter directive. You should use the lt comparator to filter for only those blog posts with fewer than 10 dislikes.
Here’s the query.
{
authors_and_ratings(func: ge(rating, 4.0)) {
author_name
rating
published @filter(lt(dislikes, 10)) {
title
likes
dislikes
tagged {
tag_name
}
}
}
}
The query returns:
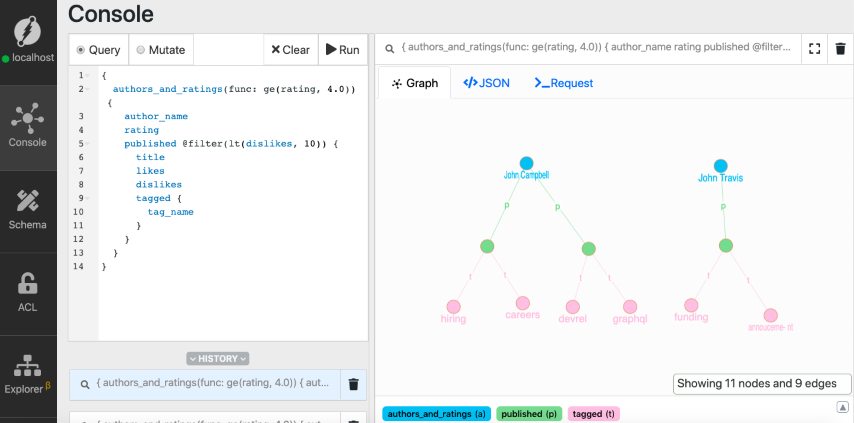
Now, we only have three blogs in the result. The blog with 12 dislikes is filtered out.
Notice that the blog posts are associated with a series of tags.
Let’s run the following query and find all the tags in the database.
{
all_tags(func: has(tag_name)) {
tag_name
}
}
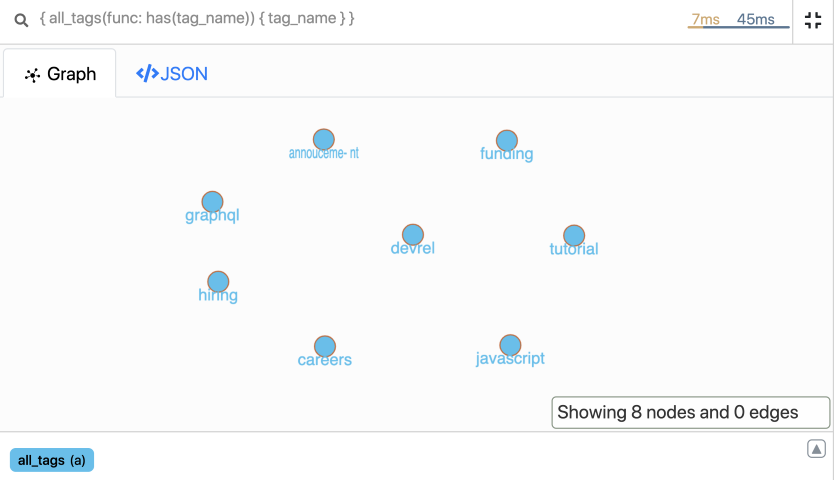
We got all the tags in the database. My favorite tag is devrel. What’s yours?
In our next section, let’s find all the blog posts which are tagged devrel.
Querying string predicates
The tag_name predicate represents the name of a tag. It is of type string. Here are the steps to fetch all blog posts which are tagged devrel.
- Find the root node with the value of
tag_namepredicate set todevrel. We can use theeqcomparator function to do so. - Don’t forget to add an index to the
tag_namepredicate before you run the query. - Traverse starting from the node for
devreltag along thetaggededge.
Let’s start by adding an index to the tag_name predicate. Go to Ratel, click tag_name predicate from the list.
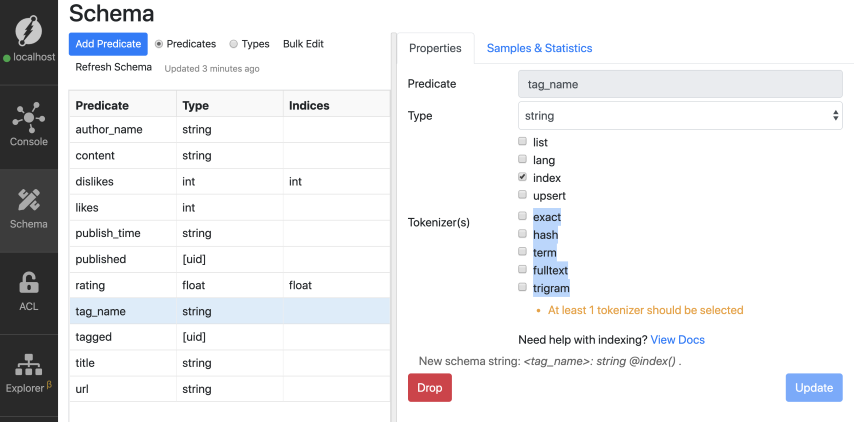
You can see that there are five choices for indexes that can be applied to any string predicate. The fulltext, term, and trigram are advanced string indexes. We’ll discuss them in detail in our next episode.
There are a few constraints around the use of string type indexes and the comparator functions.
For example, only the exact index is compatible with the le, ge,lt, and gt built-in functions. If you set a string predicate with any other index and run the above comparators, the query fails.
Although, any of the five string type indexes are compatible with the eq function, the hash index used with the eq comparator would normally be the most performant.
Let’s add the hash index to the tag_name predicate.
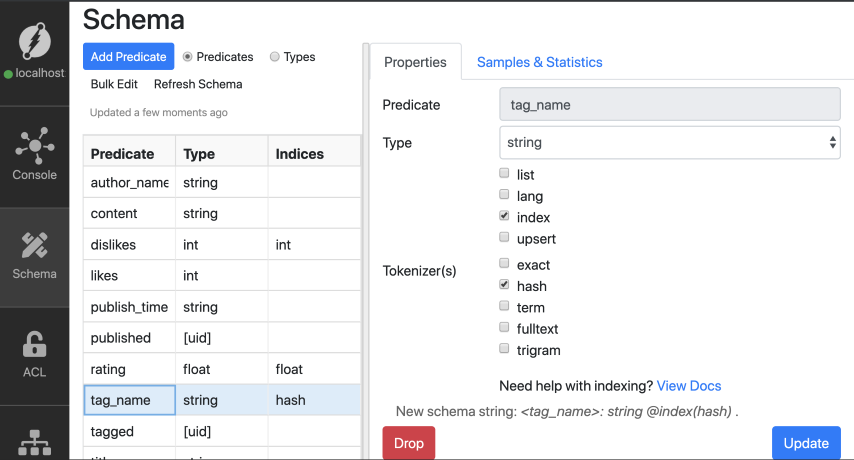
Let’s use the eq comparator and fetch the root node with tag_name set to devrel.
{
devrel_tag(func: eq(tag_name,"devrel")) {
tag_name
}
}
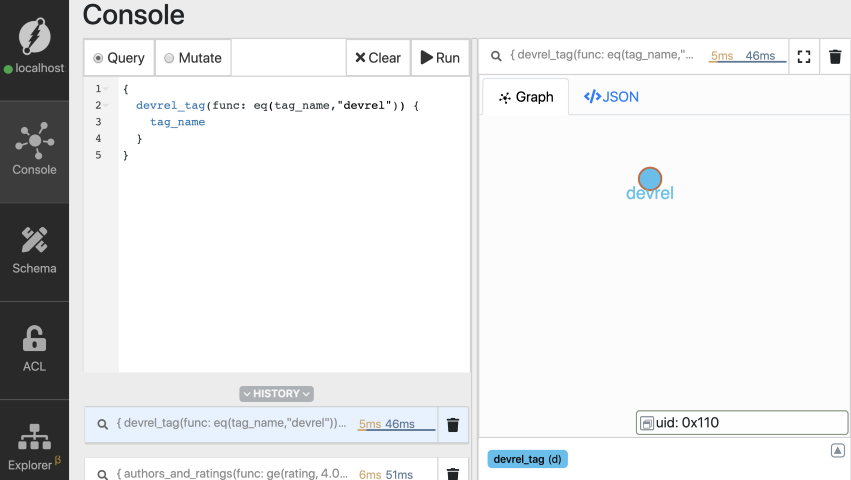
We finally have the node we wanted!
We know that the blog post nodes are connected to their tag nodes via the tagged edges. Do you think that a traversal from the node for devrel tag should give us the blog posts? Let’s try it out!
{
devrel_tag(func: eq(tag_name,"devrel")) {
tag_name
tagged {
title
content
}
}
}
Looks like the query didn’t work! It didn’t return us the blog posts! Don’t be surprised as this is expected.
Let’s observe our Graph model again.
We know that the edges in Dgraph have directions. You can see that the tagged edge points from a blog post node to a tag node.
Traversing along the direction of an edge is natural to Dgraph. Hence, you can traverse from any blog post node to its tag node via the tagged edge.
But to traverse the other way around requires you to move opposite to the direction of the edge. You can still do so by adding a tilde(~) sign in your query. The tilde(~) has to be added at the beginning of the name of the edge to be traversed.
Let’s add the tilde (~) at the beginning of the tagged edge and initiate a reverse edge traversal.
{
devrel_tag(func: eq(tag_name,"devrel")) {
tag_name
~tagged {
title
content
}
}
}
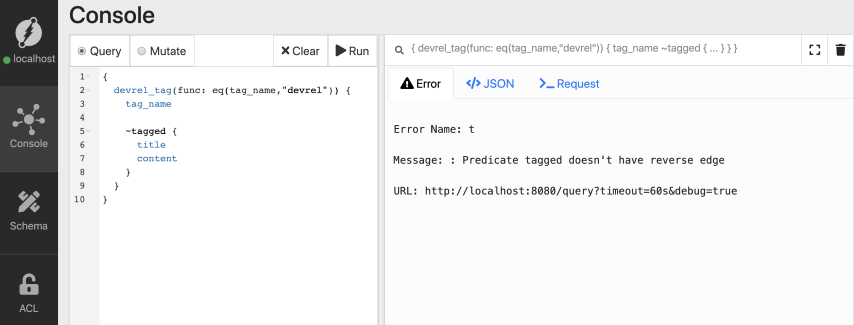
We got an error!
Reverse traversals require an index on their predicate.
Let’s go to Ratel and add the reverse index to the edge.
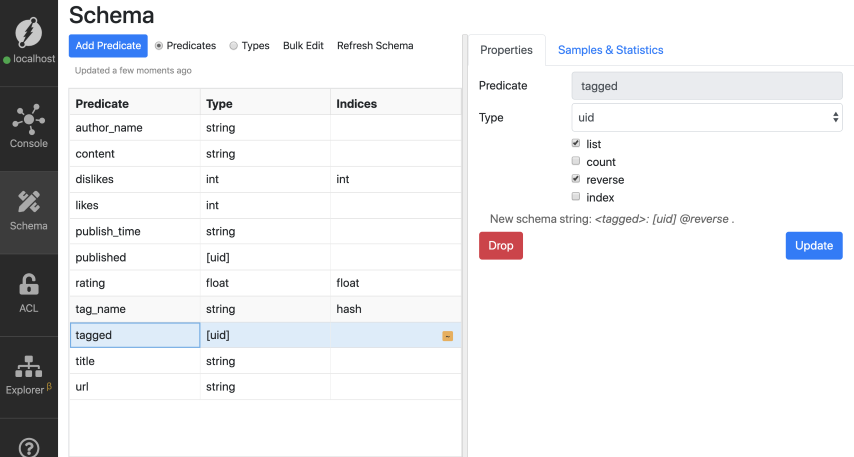
Let’s re-run the reverse edge traversal.
{
devrel_tag(func: eq(tag_name, "devrel")) {
tag_name
~tagged {
title
content
}
}
}
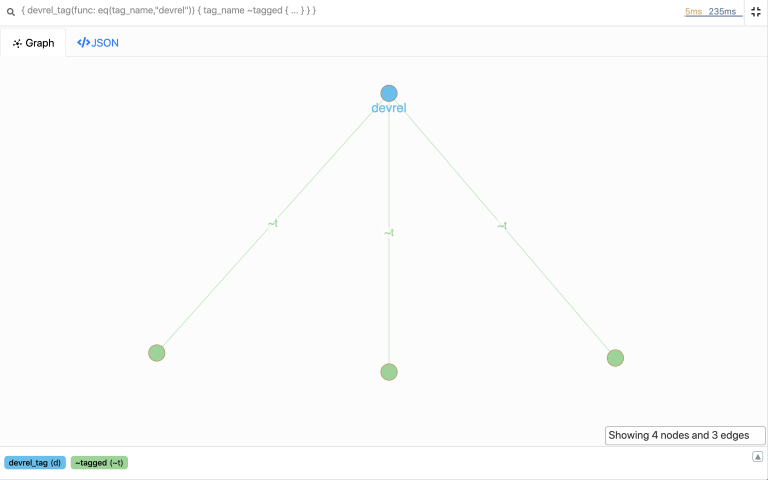
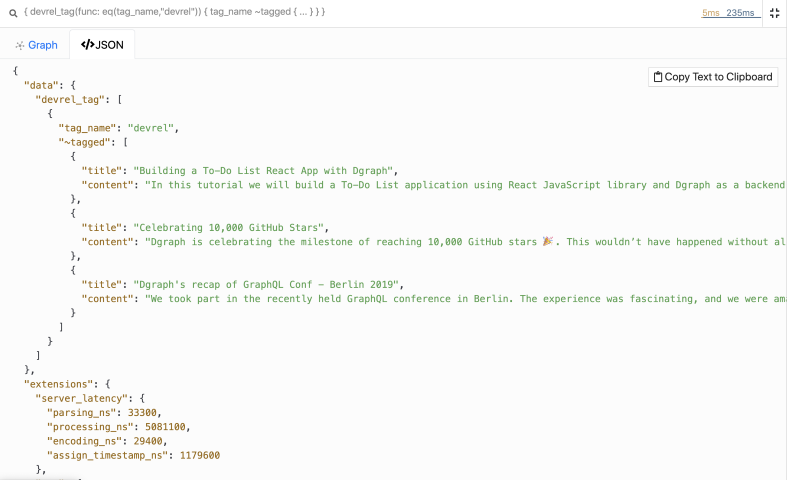
Phew! Now we got all the blog posts that are tagged devrel.
Similarly, you can extend the query to also find the authors of these blog posts. It requires you to reverse traverse the published predicate.
Let’s add the reverse index to the published edge.
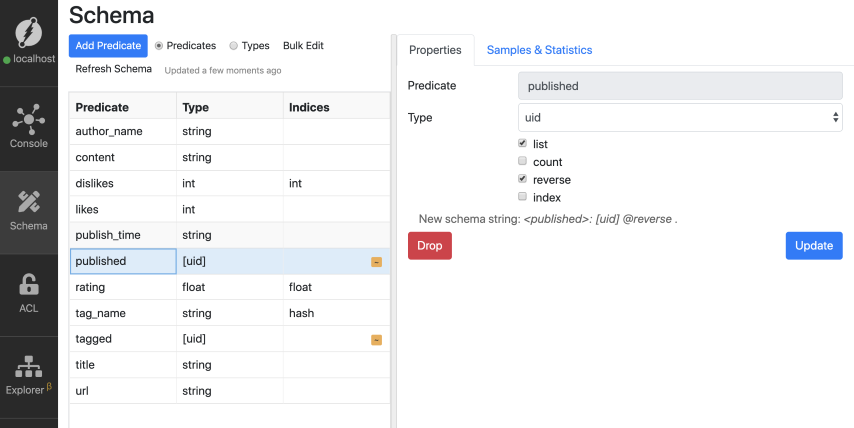
Now, let’s run the following query.
{
devrel_tag(func: eq(tag_name,"devrel")) {
tag_name
~tagged {
title
content
~published {
author_name
}
}
}
}
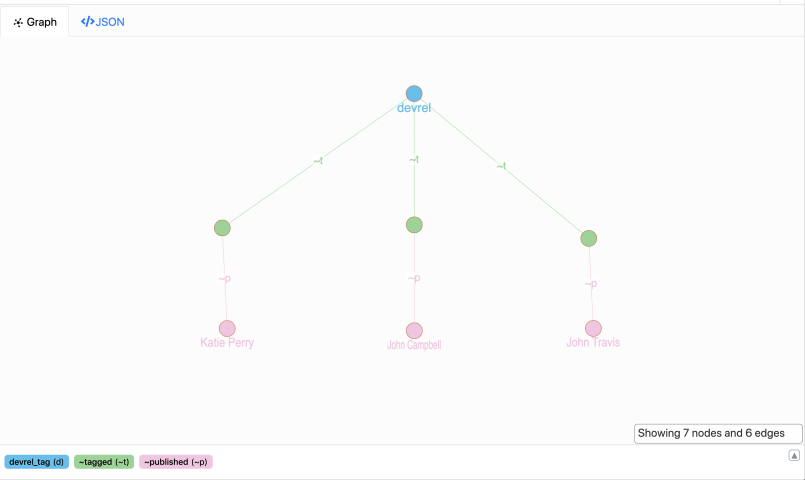
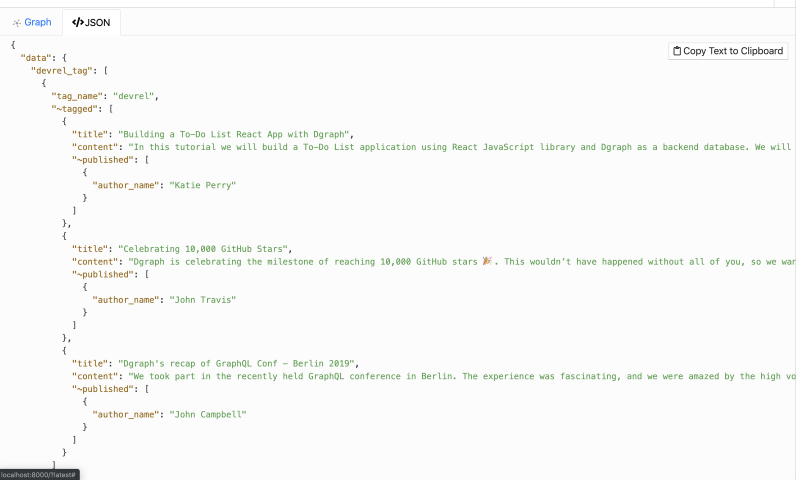
With our previous query, we traversed the entire graph in reverse order. Starting from the tag nodes, we traversed up to the author nodes.
Summary
In this tutorial, we learned about basic types, indexes, filtering, and reverse edge traversals.
Before we wrap up, here’s a sneak peek into our next tutorial.
Did you know that Dgraph offers advanced text search capabilities? How about the geo-location querying capabilities?
Sounds interesting?
Check out our next tutorial of the getting started series here.
Need Help
- Please use discuss.dgraph.io for questions, feature requests, bugs, and discussions.